
The proliferation of fake news on the Internet has been a problem for a while, and not just because that’s what Donald Trump likes to call any news story he disagrees with. Some sites exist simply to post any half-truth or outright falsehood that will get enough people angry to drive traffic to their advertisers.
Facebook is aware of the problem, and has been trying various ineffective methods of fighting it. The latest attempt sparked a controversy today that demonstrates it still has a ways to go.
Last night, Christian satire site The Babylon Bee posted a news story about CNN purchasing an industrial-sized washing machine, for the purpose of “spinning” news before publication. The story was itself a satirical take on how many on the right consider CNN to be liberal propaganda and, hence, “fake news.”
The custom-made device allows CNN reporters to load just the facts of a given issue, turn a dial to “spin cycle,” and within five minutes, receive a nearly unrecognizable version of the story that’s been spun to fit with the news station’s agenda.
Subsequently, hoax-debunking site Snopes posted a “fact check” of the story, saying that it should have been immediately obvious as a satirical spoof, even if it wasn’t marked as such on the bottom of the page, but “some readers missed that aspect of the article and interpreted it literally.” So, naturally, they declared it “false” and that was that.
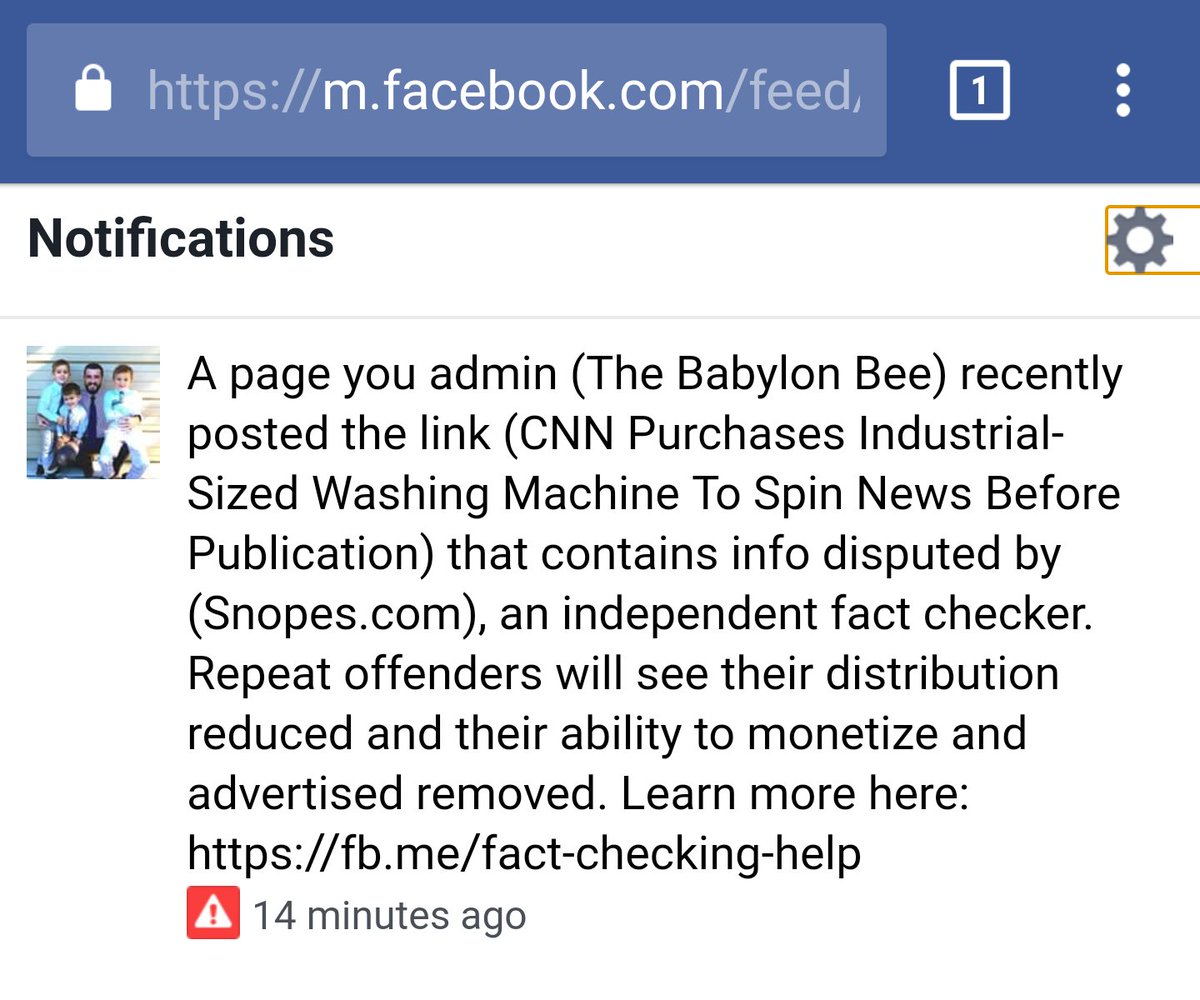
Or so we thought. But in my Facebook friends feed this morning, this little gem showed up when a friend shared the Babylon Bee story.

There was also an interface pop-up from Facebook advising me that the blue “Fact-Checker” denotes an independent fact-checking source to warn that people should look further into the story. And a story about the matter on Poynter noted that members are getting pop-up warnings before sharing the story (as Jess mentions in the image above).
And then Adam Ford, administrator of The Babylon Bee’s facebook page, shared a message he’d received from Facebook, warning that the page could be penalized if it kept posting fake news.
Really, Facebook?? pic.twitter.com/HEtBc7C0Gz
— Adam Ford (@Adam4d) March 2, 2018
Facebook sent Poynter a statement admitting that the warning was a false positive and has since been corrected, and that The Babylon Bee would not be penalized for it. And for its part, Snopes founder David Mikkelson said that they had received a number of inquiries about the story, and it was their policy to fact-check any content that might be perceived as true—including from known satire sites like The Onion—because “nothing is so obvious that at least some portion of the audience won’t question or believe it.” He also noted that Snopes doesn’t have any control over Facebook choosing to base its actions on their fact checks.
The Poynter piece also notes that the situation is complicated by sites like those I mentioned earlier, that post provocative and inflammatory falsehoods to draw viral traffic under the fig leaf of “satire.”
At root, this is simply another demonstration of how false positives can creep into any system designed to operate largely without human intervention. Given that Facebook receives such incredible amounts of traffic that there’s no way it could hire enough people to scrutinize every story individually, it’s clear that they set up automated rules to check each story.
The rule might go something like, “IF debunking site declares news story false, THEN trigger the fake-news-fighting protocol any time it shows up on Facebook.” It’s much like the kind of rules you might use in a spam email filter, to try to get rid of as much junk mail as possible while letting as much non-junk mail through as possible. But “good” emails frequently wind up in spam folders—and so “good” news stories that look a little like fake news can be mistakenly slapped with that same label. Facebook has fixed it this time (and will presumably put rules in place exempting stories from The Babylon Bee, The Onion, Duffelblog, The Borowitz Report, and other known actual satire pages now that it’s been brought to their attention), but there will surely be other false positives they couldn’t even anticipate.
And other news and opinion sites have their own axe to grind about Snopes. In its own take on the controversy, conservative news site The Federalist complains that Snopes has a habit of making false claims in its fact checks of The Federalist stories. Whether I think they’re right is not important; what matters is that Facebook has demonstrated willingness to penalize news sites based on what might in some cases boil down to a difference of political opinion. (And that’s not even getting into the fact that many people simply want to believe the hoaxes.)
Is there any reliable automated way to detect and defend against “fake” news stories without also catching too many satire, difference-of-opinion posts, and other false positives that shouldn’t be penalized? Or, conversely, without letting too many false negatives through? I have my doubts.
Even SpamAssassin, one of the smartest spam filters I’ve come across, has to be trained manually before it gets any good at picking out what’s spam and what isn’t—and then it has to be retrained and retrained again as the nature of the spam changes. And the consequences of letting a few too many spams into your inbox are naturally going to be a bit less serious than letting a few too many hoax news stories go viral.
In any case, I expect that if false positives are going to be an issue for Facebook, it won’t be too long before we see another case like this, and another. What will Facebook do then? We’ll just have to wait and see.

There is a potential good side to what we’re calling “fake” news. Readers are challenged to be less gullible and more discriminating. Helping readers spot lies, deception and distortion in prose will, I think, yield better results overall than the best algorithms we can devise.
So why don’t we crowd source this problem? Might there be enough readers out there to do what algorithms cannot?
We could have a “truthiness index” that trained, volunteer readers contribute to by interacting with a brief form that only appears to these known and accountable readers at the bottom of every published piece. Their work will produce an easily understood set of indicators relative to the type of article (opinion, analysis, satire, advertisement, infomercial, etc.).
So, do we have or can we develop the necessary training materials? Do we have the trainers? Can we recruit the readers?
Obviously, this won’t be as cheap or sanitary as hiring more coders to fashion yet more algorithms but I think it might work better by elevating the level of discernment among readers of all stripes. Readers helping readers – what a concept.
LikeLiked by 1 person
Here is an exemple of a new solution to the old problem : http://mbe.io/2H1Asg3
It is called Kialo…
LikeLike